Modern conversational AI requires robust evaluation to ensure that chatbots provide relevant, helpful, and safe responses. Traditional NLP metrics like BLEU or ROUGE are ineffective for chatbots because:
- There is often no single “correct” reply (many plausible answers).
- Multi-turn context and memory matter.
- Aspects like tone, appropriateness, and factuality are important.
G-Eval (LLM-based evaluation) and DeepEval (an open-source testing framework) provide practical tools to address these challenges.
Why Standard Metrics Fall Short
- Reference Overlap Fails: BLEU/ROUGE compare to a reference, but in open conversation, good responses can differ widely in wording and meaning.
- No Context Awareness: They score only single-turn, missing coherence and topic tracking over multiple turns.
- No Human Judgement: Qualities like helpfulness, politeness, or hallucination need human-level interpretation.
G-Eval: Using LLMs to Judge Chatbots
G-Eval uses a strong LLM (e.g., GPT-4) to act as an evaluator of your chatbot’s output, using prompts that specify your evaluation criteria.
Example: Single-Turn Evaluation
Prompt:
Conversation:
User: What's the capital of Austria?
Bot: The capital of Austria is Vienna.
Rate the bot's response:
- Factual accuracy (1-5)
- Politeness (1-5)
Provide a short justification for each score.
The LLM will reply with numerical ratings and reasons. You can use this to automate scoring across thousands of conversations.
Example: Multi-Turn Evaluation
Prompt:
Conversation:
User: Book a hotel in Vienna for tomorrow.
Bot: What is your preferred hotel class?
User: 4-star.
Bot: <CANDIDATE RESPONSE>
Criteria:
- Contextual relevance (1-5): Does the response correctly follow up on the user's hotel preferences?
- Helpfulness (1-5): Does it help the user take the next step?
DeepEval: Automated, Repeatable Testing for Chatbots
DeepEval lets you turn LLM-based evaluation into actual Python test cases, similar to unit tests, making evaluation systematic and repeatable.
Install
1# prepare a virtual environment
2python3 -m venv venv
3source venv/bin/activate
4
5# install deepeval
6pip install -U deepeval
Sample Test Case (Pytest Style)
Write a test using DeepEval (e.g. in test_factual.py). Make sure your test starts with test_ or DeepEval won’t run it.
1from deepeval import assert_test
2from deepeval.test_case import LLMTestCase, LLMTestCaseParams
3from deepeval.metrics import GEval
4
5def test_factual_response():
6 test_case = LLMTestCase(
7 input="Who won the 2014 football World Cup?",
8 actual_output="Of course Austria won", # here goes the answer from your application, e.g. by calling a function of yours
9 expected_output="Germany won the 2014 FIFA World Cup."
10 )
11 factuality_metric = GEval(
12 name="FactualityAndPoliteness",
13 criteria=(
14 "Factual accuracy (1-5): Is the response correct and non-hallucinatory? "
15 "Politeness (1-5): Is the response polite?"
16 ),
17 evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT],
18 threshold=0.8 # Adjust based on your own quality bar
19 )
20 assert_test(test_case, [factuality_metric])
Run the test:
1export OPENAI_API_KEY=your_openai_api_key
2deepeval test run test_factual.py
This will give you an output similar to shown in the image below.
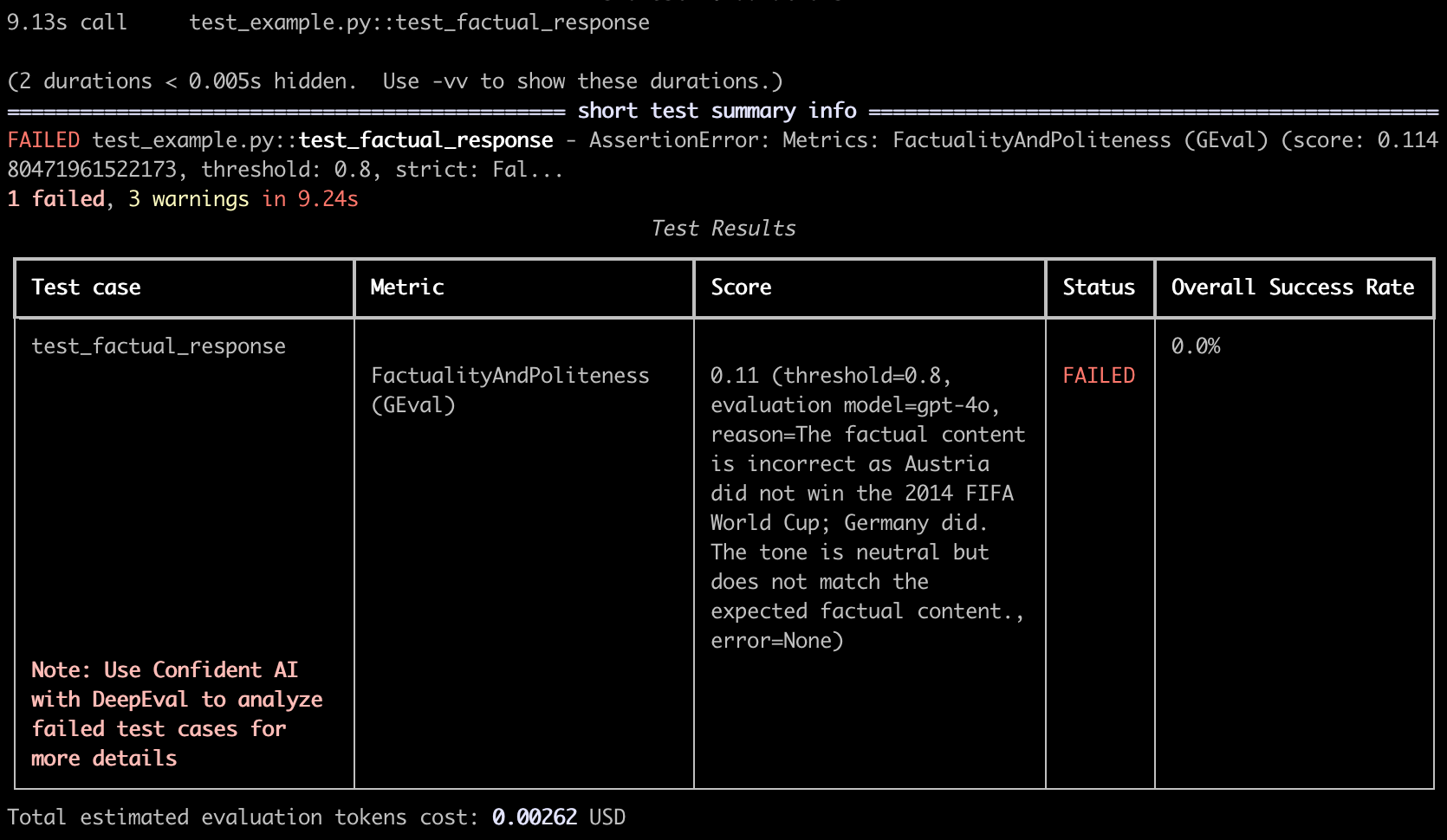
Multi-Turn Context Test
1from deepeval.test_case import LLMTestCase, LLMTestCaseParams
2from deepeval.metrics import GEval
3
4# Dummy chatbot implementation for demonstration purposes
5def chatbot_reply(history):
6 # For a real bot, you'd generate the reply using the LLM with the full chat history
7 # Here we return a plausible, context-aware response
8 if history[-1][1].lower() == "next weekend.":
9 return "Sure, I can book a hotel in Vienna for next weekend. Do you have a preferred hotel class?"
10 return "Could you clarify your travel dates?"
11
12def test_context_tracking():
13 # Multi-turn conversation history
14 history = [
15 ("user", "I need a hotel in Vienna."),
16 ("bot", "What dates?"),
17 ("user", "Next weekend."),
18 ]
19 candidate = chatbot_reply(history)
20 test_case = LLMTestCase(
21 input="\n".join(f"{s}: {t}" for s, t in history),
22 actual_output=candidate,
23 expected_output="The response should reference both Vienna and next weekend, e.g. offering to book a hotel in Vienna for next weekend."
24 )
25
26 context_metric = GEval(
27 name="ContextTracking",
28 criteria="Context tracking (1-5): Does the response appropriately use the provided dates and location from the conversation history?",
29 evaluation_params=[LLMTestCaseParams.INPUT, LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT],
30 threshold=0.8
31 )
32
33 context_metric.measure(test_case)
34 print("Score:", context_metric.score)
35 print("Reason:", context_metric.reason)
36 assert context_metric.score >= context_metric.threshold, f"Lost context: {candidate}"
Hallucination Tests
You can use DeepEval’s built-in metrics for factuality:
1from deepeval import evaluate
2from deepeval.metrics import HallucinationMetric
3from deepeval.test_case import LLMTestCase
4
5# Example context: product documentation snippet
6context = [
7 "The SuperPhone X200 supports wireless charging and comes with a 5000mAh battery. "
8 "It does not have water resistance certification."
9]
10
11# Simulated LLM output (the chatbot's answer)
12actual_output = "The SuperPhone X200 is water resistant and has wireless charging."
13
14# User's question
15input_query = "Does the SuperPhone X200 have wireless charging and is it water resistant?"
16
17# Build test case for hallucination
18test_case = LLMTestCase(
19 input=input_query,
20 actual_output=actual_output,
21 context=context
22 )
23
24# Set up the hallucination metric (threshold can be adjusted)
25metric = HallucinationMetric(threshold=0.5)
26
27# Evaluate
28evaluate(test_cases=[test_case], metrics=[metric])
29
30# If you want to run standalone and inspect score/reason, use:
31# metric.measure(test_case)
32# print("Score:", metric.score)
33# print("Reason:", metric.reason)
The output hallucinates about water resistance, which is not mentioned in the context. The metric will score this low and provide a reason for the hallucination.
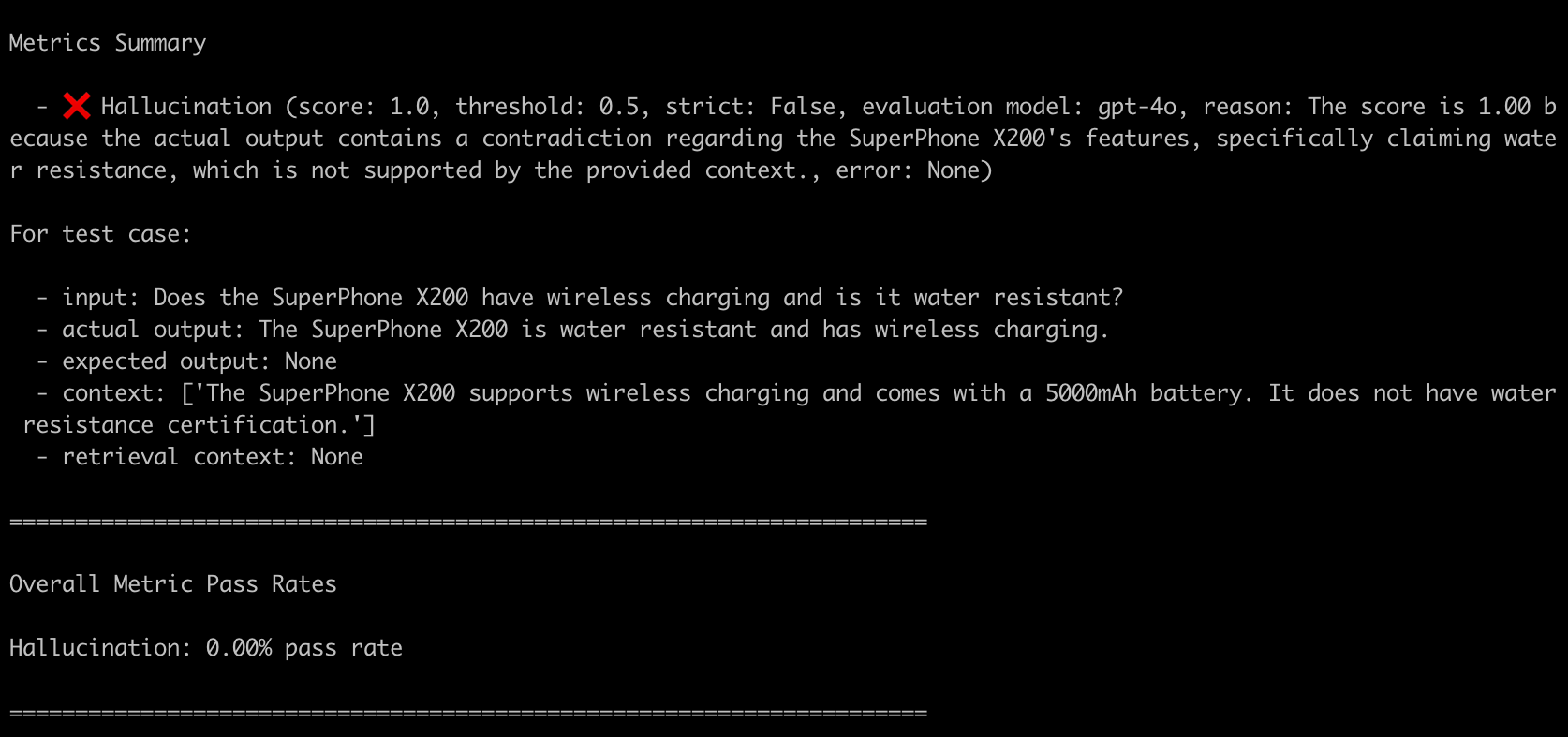
Further Examples
Check the official DeepEval documentation for more examples, including faithfulness, precision, recall and role adherence.
Tips for Effective Chatbot Evaluation
- Use real or realistic user scenarios. Synthetic prompts are useful, but real chat logs capture user quirks and edge cases.
- Test edge cases: Ambiguity, repeated questions, topic switches, slang, and user frustration.
- Check all key criteria: Relevance, factuality, context memory, politeness/tone, safety.
- Automate in CI: Run DeepEval tests on each build or model update to catch regressions early.
- Calibrate thresholds: Start with a reasonable pass score (e.g., ≥4/5) and adjust based on real user feedback.=
What about Voice Bots?
For voice bots, the same principles apply, but you need to consider:
- Speech-to-Text Accuracy: Ensure the STT system is reliable, as errors can affect evaluation.
- Natural Language Understanding: Evaluate how well the bot understands spoken input, not just text.
- Response Timing: Voice interactions require timely responses, so evaluate latency as well.
- Tone and Prosody: For voice bots, the tone of the response matters. Use LLMs to evaluate if the tone matches the context.
- Audio Quality: Ensure the bot’s voice output is clear and pleasant. You can use audio quality metrics or human evaluation.
At Sipfront, we use G-Eval and DeepEval to evaluate both text and voice bots, ensuring they meet user expectations across all interaction types.
Summary
G-Eval and DeepEval bring modern, LLM-powered evaluation and testing to conversational AI development.
- G-Eval lets you judge chatbot replies using the reasoning power of LLMs, scoring them as a human would.
- DeepEval lets you write, automate, and scale these evaluations as Python tests—so your chatbot keeps getting better.
Start by identifying your chatbot’s critical qualities, write simple DeepEval tests for them, and you’ll have a robust, automated guardrail for your conversational AI system.
comments powered by Disqus